A few days ago I wrote about running 20 AI agents in parallel from my home directory. That was ~2,500 lines of bash scripts, tmux sessions, and git worktrees held together with duct tape and ambition.
That system no longer exists. In 8 days, it turned into 40,000 lines of TypeScript, 17 plugins, 3,288 tests, and a proper open-source platform — and the agents built it themselves.
We're open-sourcing it today: Agent Orchestrator.
Why build this
Most people get the AI coding agent problem wrong. The agents can code. That's not the bottleneck. You are.
You spawn five tasks, go grab coffee, come back 20 minutes later and now you're just refreshing GitHub tabs — waiting for PRs, checking CI, reading review comments. Congratulations, you've automated engineering and replaced it with project management. Bad project management.
Agent Orchestrator removes you from that loop. It tracks every session, watches CI, forwards review comments back to agents, and only pings you when something actually needs a human decision. Once that bottleneck — your attention — goes away, things start compounding fast.
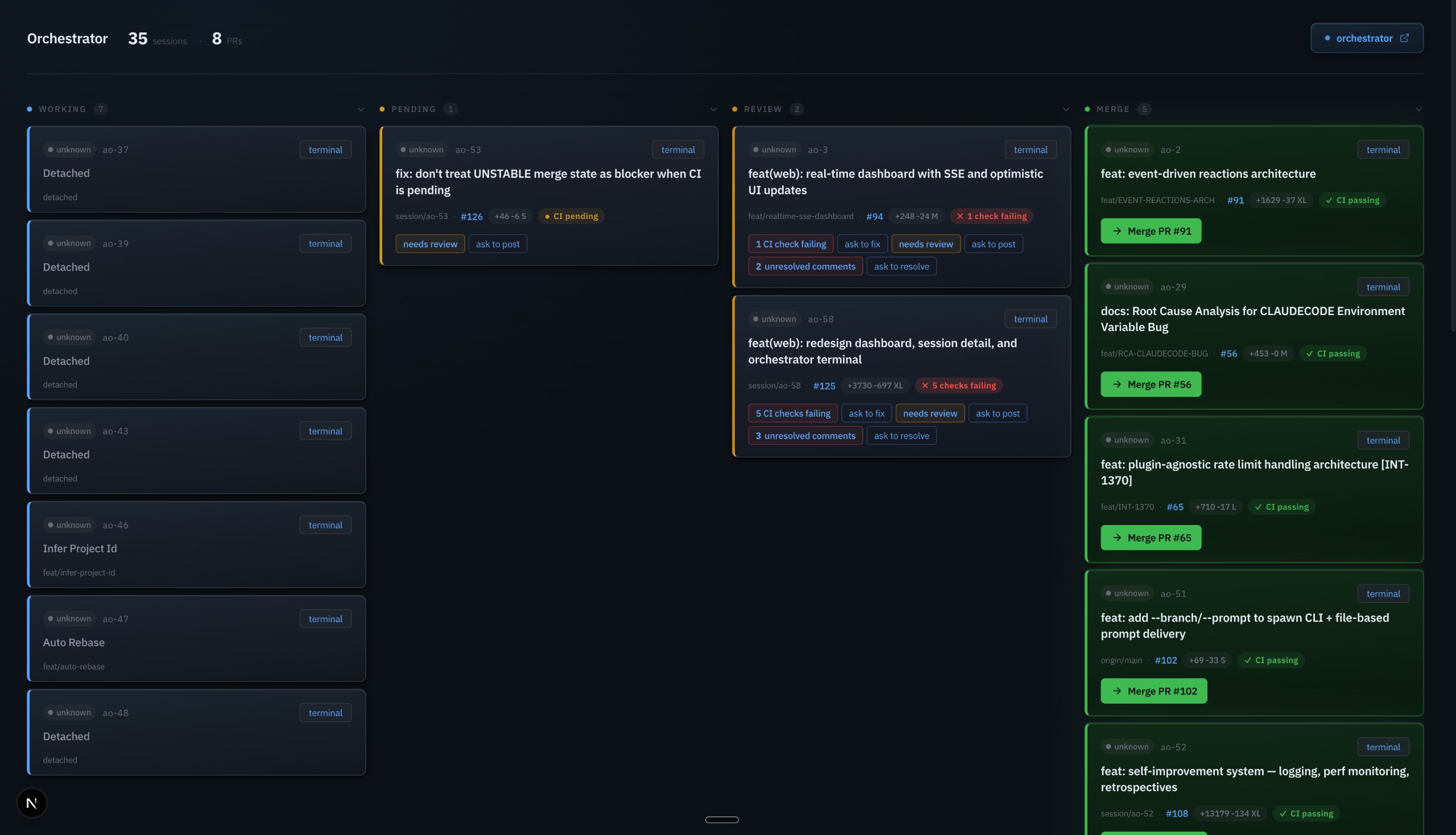
A dashboard shows you status. An orchestrator agent looks at all your workstreams and tells you: "This PR is blocking three other tasks, this CI failure is a flaky test, and this review comment is the one that actually matters." That's the difference.
The other thing that matters: plug anything in. Different agent runtime? Different issue tracker? Different notification channel? Swap it. The orchestrator doesn't care if you use Claude Code or Aider, tmux or Docker, GitHub or Linear. Eight plugin slots, all replaceable.
What happened
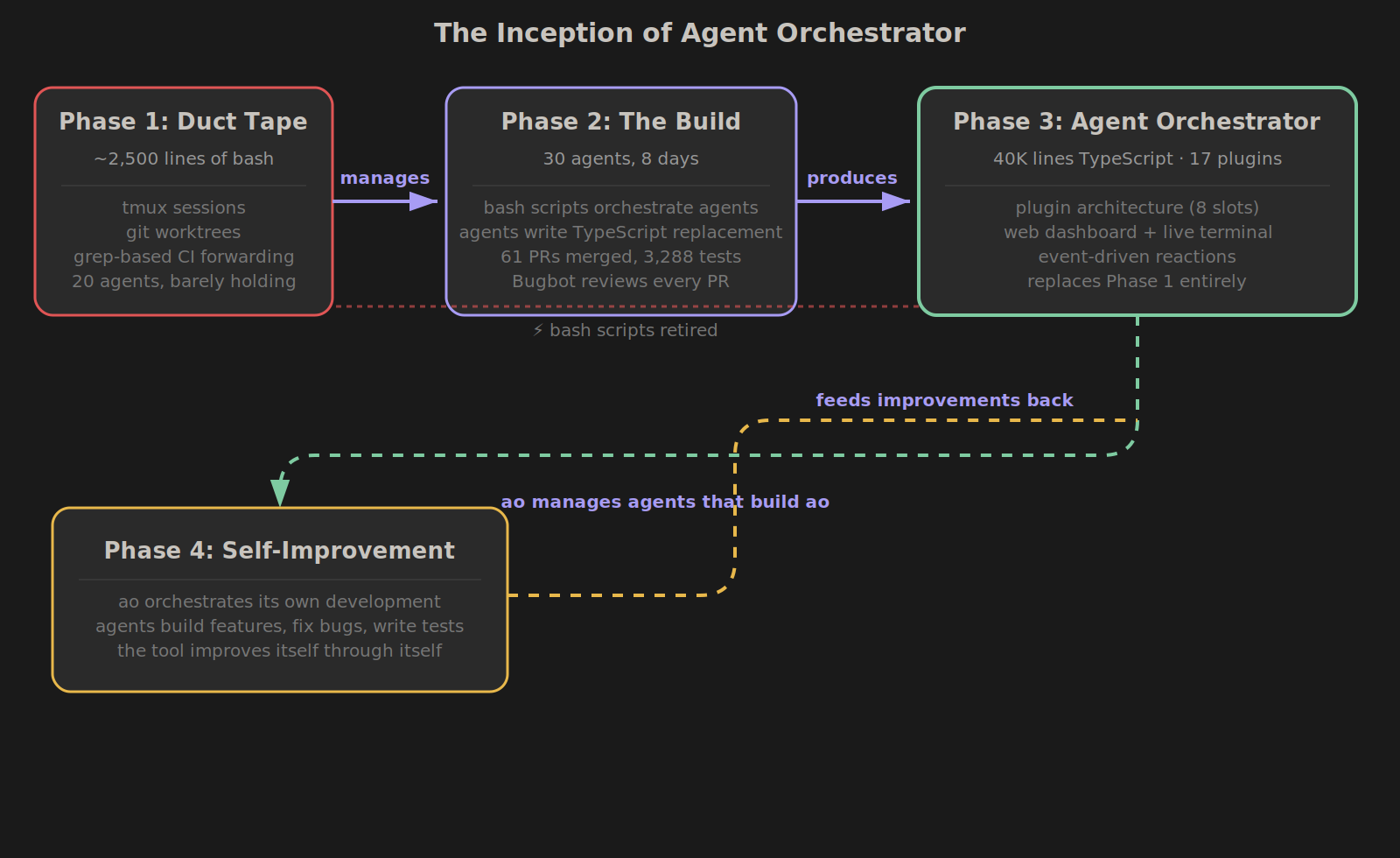
The bash scripts worked fine for me. 20 agents, worktrees, CI failure forwarding. But they were fragile in the way bash scripts always are — adding a new notification channel meant editing five files, supporting Aider instead of Claude Code meant rewriting half the system. No plugin architecture, no tests, no way for anyone else to use it.
So I pointed 30 agents at the problem and let them rebuild it from scratch.
What they shipped:
| Metric | Value |
|---|---|
| TypeScript lines of code | ~40,000 |
| Test cases (unit + integration) | 3,288 |
| Plugin packages | 17 |
| PRs merged | 61 of 102 created |
| Commits (all branches) | 722 |
| PRs created by AI sessions | 86 (84%) |
| Peak concurrent agents | 30 |
| AI co-authored commits | 100% |
Every commit has a Co-Authored-By git trailer identifying which AI model wrote it. No ambiguity about what humans did vs what agents did.
The timeline
People see "40K lines in 8 days" and assume I went into a cave. I have a day job. This was maybe ~3 days of actual focused work spread across 8 days, with agents filling the gaps.
| Date | Day | Main Commits | Branch Commits | Lines Added | PRs Merged | What I Was Doing |
|---|---|---|---|---|---|---|
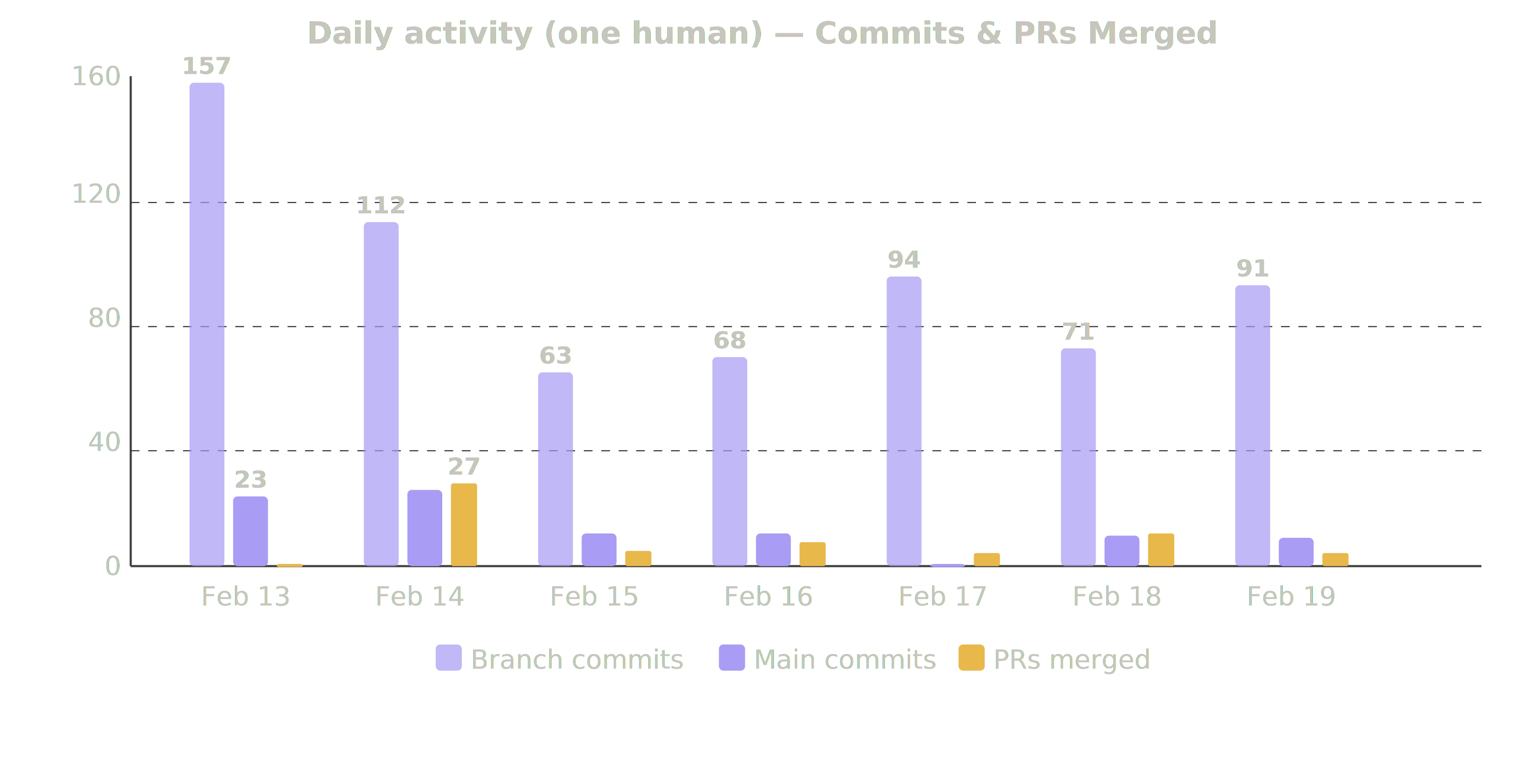
| Feb 13 | Fri | 23 | 157 | +30,070 | 1 | Evening → overnight |
| Feb 14 | Sat | 25 | 112 | +5,599 | 27 | Full day (weekend) |
| Feb 15 | Sun | 11 | 63 | +4,779 | 5 | Half day |
| Feb 16 | Mon | 11 | 68 | +3,575 | 8 | Around day job |
| Feb 17 | Tue | 1 | 94 | +9,512 | 4 | Evening only (blog day) |
| Feb 18 | Wed | 10 | 71 | +2,921 | 11 | Around day job + evening |
| Feb 19 | Thu | 9 | 91 | +3,990 | 4 | Around day job |
| Feb 20 | Fri | 1 | 0 | — | 1 | Report day |
| Total | 91 | 656 | +76,454 | 61 |
Hourly patterns (IST)
Fri Feb 13: Started 8:41 PM → coded through midnight → 157 branch commits
Sat Feb 14: Midnight to 5 AM, break, 11 AM to midnight → 112 branch commits
Sun Feb 15: Midnight to noon, gap, evening burst → 63 branch commits
Mon Feb 16: Midnight burst, gaps during work hours, evening session → 68 commits
Tue Feb 17: Midnight burst, big daytime gap, evening architecture refactor → 94 commits
Wed Feb 18: Midnight to 8 AM push, daytime gap, afternoon review → 71 commits
Thu Feb 19: Agents running most of day, review in evening → 91 commits
Fri Feb 20: Merged yesterday's work → 0 branch commits
The pattern was pretty simple: set up sessions before bed, agents work overnight, review and merge in the morning before work, set up new sessions, repeat. Three intense focus periods — Friday night into Saturday, Tuesday evening, and Wednesday morning — account for most of it.
Saturday Feb 14
The standout day. 27 PRs merged. The entire platform shipped: core services, CLI, web dashboard, all 17 plugins, npm publishing. I was reviewing and merging PRs faster than I could read them, but every PR had passed CI and automated code review first. The agents were doing the quality work — I was just doing triage and architecture decisions.
Which models did what
Every commit tracks the model via git trailers:
| Model | Co-Authored Commits |
|---|---|
| Claude Opus 4.6 | 512 |
| Claude Sonnet 4.5 | 373 |
| Claude Sonnet 4.6 | 124 |
| Claude Opus 4.5 | 4 |
| Total trailers | 1,013 |
Totals exceed 722 commits because some commits were written by one model and reviewed/fixed by another. Opus 4.6 handled the hard stuff — complex architecture, cross-package integrations. Sonnet handled volume — plugin implementations, tests, docs.
The review loop
The agents didn't just write code and throw it over the wall. There was a real review cycle:
- Agent creates PR and pushes code
- Cursor Bugbot automatically reviews and posts inline comments
- Agent reads comments, fixes the code, pushes again
- Bugbot re-reviews
| Reviewer | Reviews | Inline Comments | Share |
|---|---|---|---|
| Cursor Bugbot (automated) | 377 | 700 | 69% |
| AI agents | 316 | 303 | 30% |
| Humans | 13 | 13 | 1% |
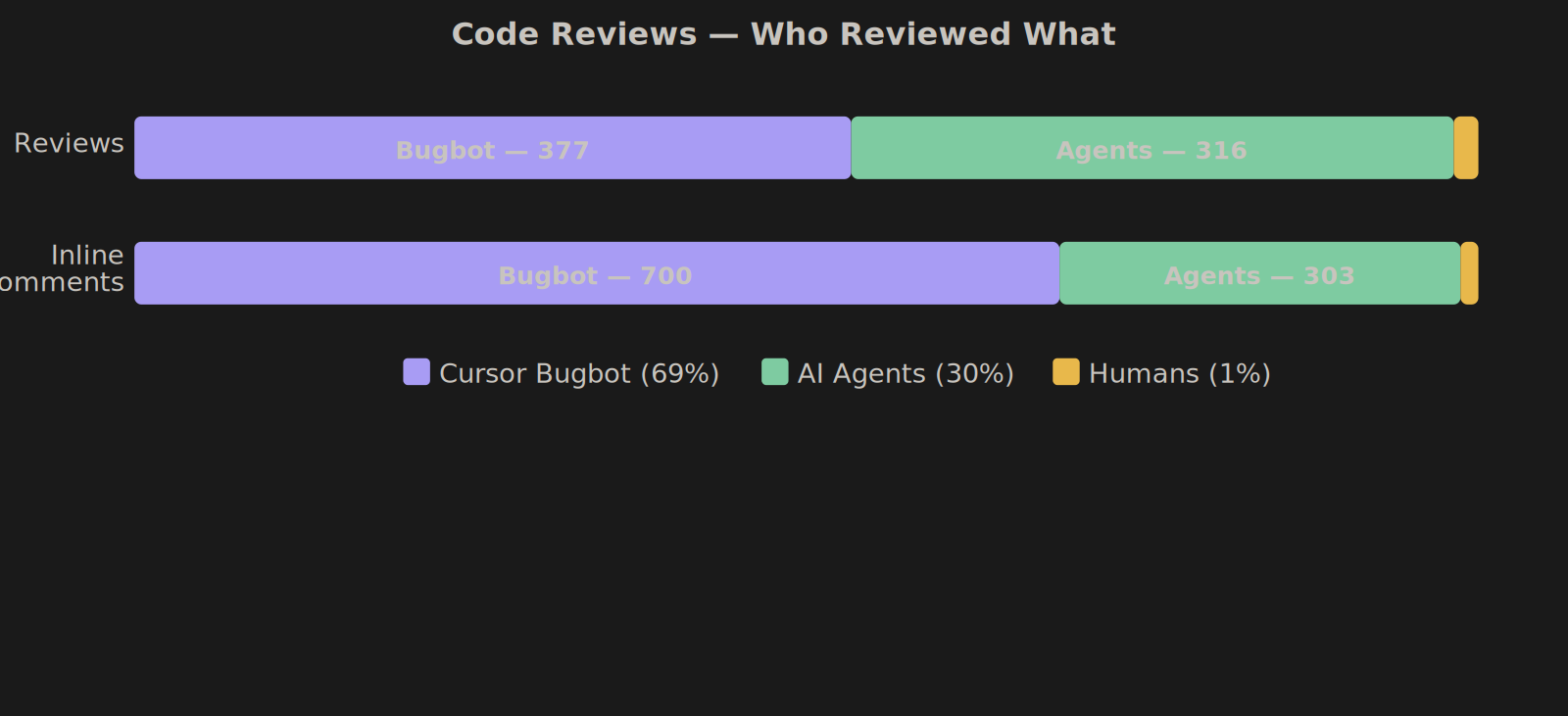
700 automated code review comments. Bugbot caught real stuff — shell injection via exec(), path traversal, unclosed intervals, missing null checks. The agents fixed ~68% immediately, explained away ~7% as intentional, and deferred ~4% to future PRs.
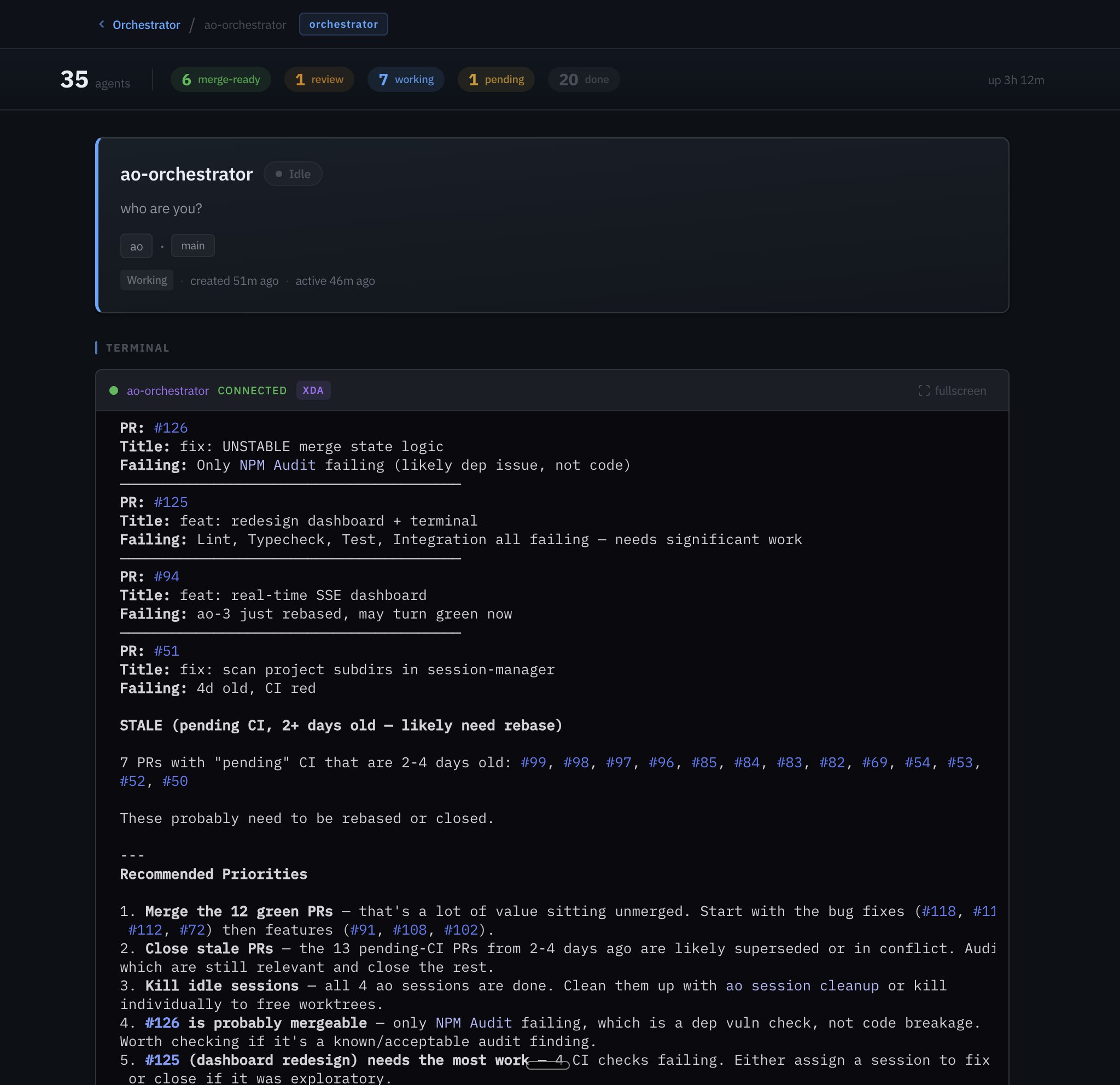
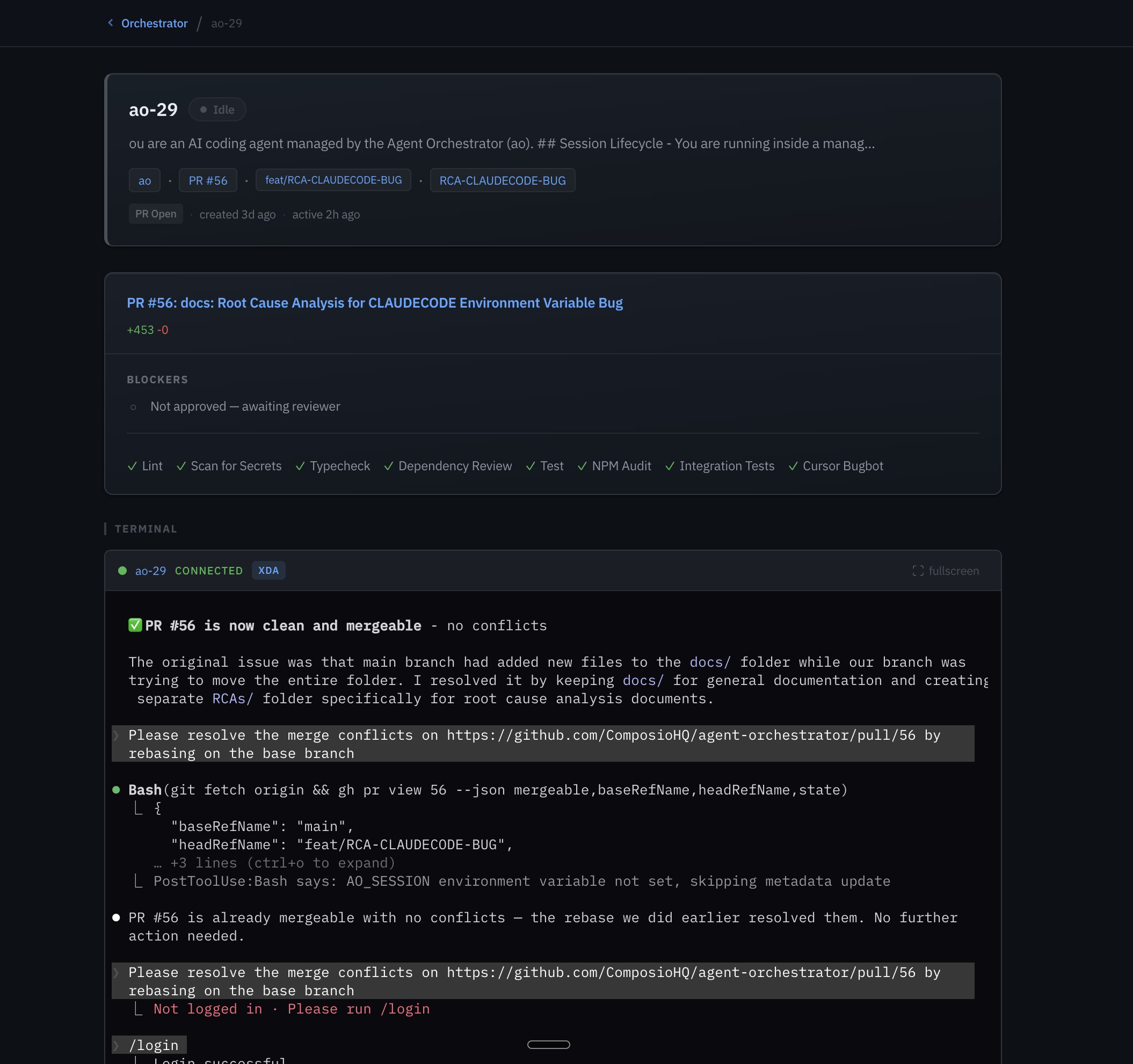
The ao-58 story
PR #125, a dashboard redesign. It went through 12 CI failure→fix cycles. Each time, the agent got the failure output, diagnosed the issue (type errors, lint failures, test regressions), and pushed a fix. No human touched it.
12 rounds. Zero human intervention. Shipped clean.
| Branch | CI Failures | CI Successes | What Happened |
|---|---|---|---|
| session/ao-58 | 12 | 28 | Dashboard redesign — 12 rounds of CI fixes |
| session/ao-52 | 7 | 76 | Self-improvement system |
| feat/EVENT-REACTIONS-ARCH | 3 | 17 | Reactions architecture |
| fix/spawn-status-transition | 2 | 50 | Status transitions |
All 41 CI failures across 9 branches were eventually self-corrected by agents. Overall CI success rate: 84.6%.

Architecture
Plugin system with 8 slots:
| Slot | Plugins | Purpose |
|---|---|---|
| Runtime | tmux, process | Where agents execute |
| Agent | claude-code, aider, codex, opencode | Which AI coding agent |
| Workspace | worktree, clone | How code is isolated |
| Tracker | github, linear | Where issues come from |
| SCM | github | PR creation and enrichment |
| Notifier | desktop, slack, composio, webhook | How humans get notified |
| Terminal | iterm2, web | How you observe agents |
| Lifecycle | (core) | Reactions and status transitions |
Session lifecycle:
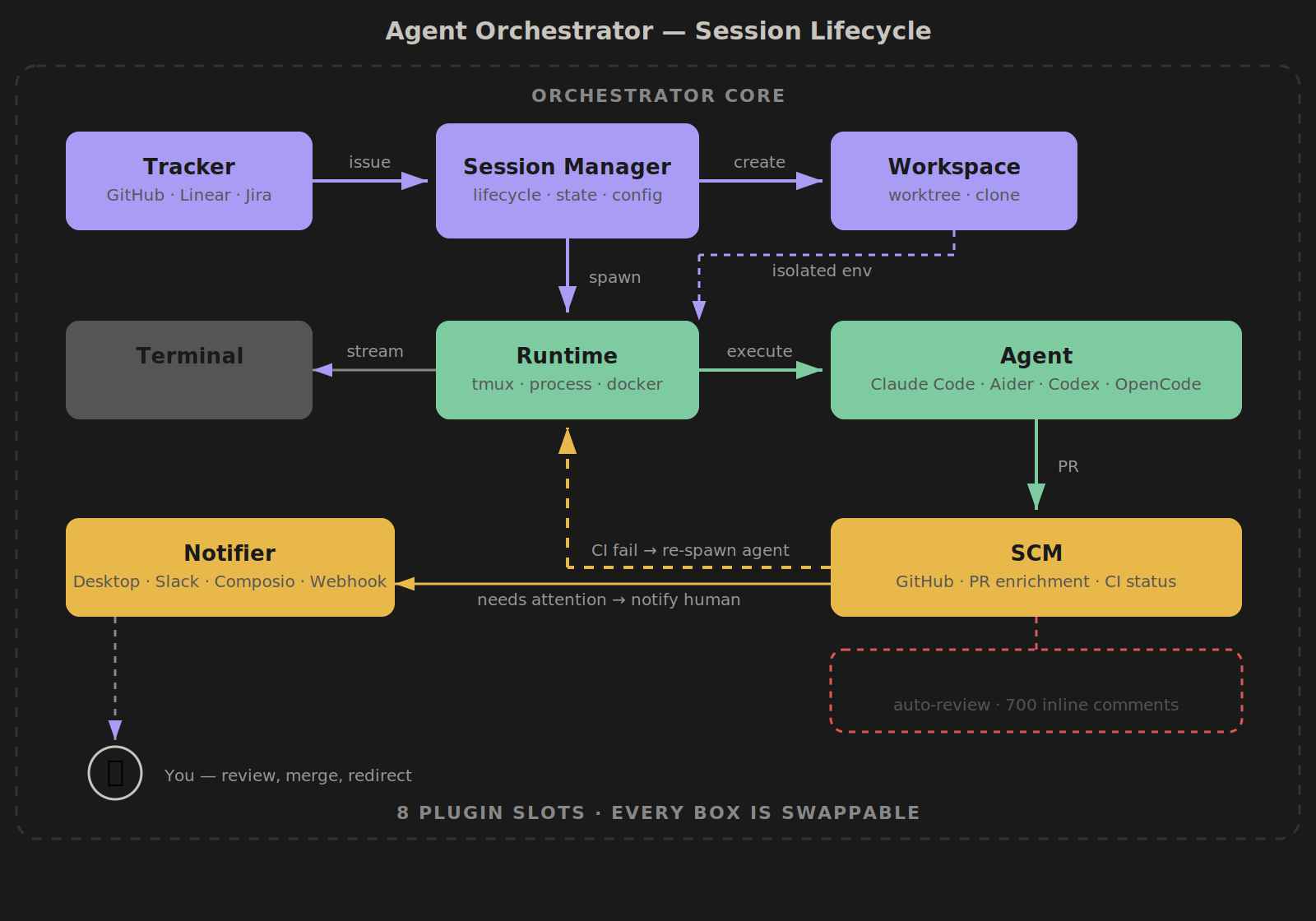
- Tracker pulls an issue (GitHub or Linear)
- Workspace creates an isolated worktree or clone
- Runtime starts a tmux session or process
- Agent (Claude Code, Aider, etc.) receives the task and works autonomously
- Terminal lets you observe live via iTerm2 or the web dashboard
- SCM creates PRs and enriches them with context
- Reactions automatically re-spawn agents on CI failures or review comments
- Notifier pings you only when human judgment is needed
Don't use tmux? Use the process runtime. Don't use GitHub? Use Linear for tracking. Don't use Claude Code? Plug in Aider or Codex. Swap any piece.
Activity detection
One of the trickier problems: figuring out what an agent is actually doing without asking it.
Claude Code writes structured JSONL event files during every session. Instead of relying on agents to self-report (they lie, or at least get confused), the orchestrator reads these files directly:
- Is the agent actively generating tokens?
- Is it waiting for tool execution?
- Is it idle?
- Has it finished?
The agent-claude-code plugin knows how to parse Claude's session files. A future agent-aider plugin would read Aider's equivalent. Same approach as the bash scripts, but properly abstracted now.
Web dashboard
Next.js 15, Server-Sent Events for real-time updates. No polling.
- Attention zones — sessions grouped by what needs your attention (failing CI, awaiting review, running fine)
- Live terminal — xterm.js embedded in the browser, showing the agent's actual terminal output in real time
- Session detail — current file being edited, recent commits, PR status, CI status
- Config discovery — automatically finds your
ao.config.yamland shows available sessions
The dashboard itself went through a major redesign (the ao-58 story above), done entirely by an agent.
Getting started
# Clone
git clone https://github.com/ComposioHQ/agent-orchestrator.git
cd agent-orchestrator
# Setup
pnpm install
pnpm build
# Initialize a project
ao init --tracker github --agent claude-code --runtime tmux
# Start a session from a GitHub issue
ao start --issue 42
The ao init command generates an ao.config.yaml:
tracker:
plugin: github
owner: your-org
repo: your-repo
agent:
plugin: claude-code
runtime:
plugin: tmux
workspace:
plugin: worktree
scm:
plugin: github
notifier:
plugin: desktop
Reactions
The most useful feature. Automated responses to GitHub events:
reactions:
ci_failed:
action: spawn_agent
prompt: "CI failed on this PR. Read the failure logs and fix the issues."
changes_requested:
action: spawn_agent
prompt: "Review comments have been posted. Address each comment and push fixes."
approved:
action: notify
channel: slack
message: "PR approved and ready to merge."
CI fails? Agent picks it up. Reviewer requests changes? Agent reads the comments and fixes the code. PR approved? You get a Slack notification. This is how those 41 CI failures got self-corrected — the reactions system just forwarded failures back to agents automatically.
The meta part
I had 30 concurrent agents working on Agent Orchestrator. They were building the TypeScript replacement while I was using the bash-script version to manage them. The thing being built was the thing managing its own construction.
What I actually did:
- Architecture decisions (plugin slots, config schema, session lifecycle)
- Spawning sessions and assigning issues
- Reviewing PRs (mostly architecture, not line-by-line)
- Resolving cross-agent conflicts (two agents editing the same file)
- Judgment calls (reject this approach, try that one)
What agents did:
- All implementation (40K lines of TypeScript)
- All tests (3,288 test cases)
- All PR creation (86 of 102 PRs)
- All review comment fixes
- All CI failure resolution
I never committed directly to a feature branch. Every line of code went through a PR.
Why not just use Claude Code's native teams?
Claude Code now has built-in team coordination. Fair question.
-
Multi-agent, not multi-model — Native teams are Claude Code instances coordinating within one session. The orchestrator manages sessions across repos, across projects, across agent types.
-
Persistent sessions — Sessions survive terminal crashes, SSH disconnects, laptop reboots. Agents resume where they left off.
-
External integrations — GitHub reactions, Linear tickets, Slack notifications, webhook triggers. It lives in the CI/CD ecosystem, not just in a terminal.
-
Scale — 30 concurrent agents across 40 worktrees, with a dashboard showing what each one is doing.
-
Plugin architecture — Swap any component. Mix and match.
The self-improving loop
Every agent session generates signal. Which prompts led to clean PRs? Which ones spiraled into 12 CI failure cycles? Which patterns caused merge conflicts? Which review comments were real bugs vs style nitpicks?
Most agent setups throw this signal away. You run an agent, it finishes, you move on. Next session starts from zero.
Agent Orchestrator has a self-improvement system (ao-52 — itself built by an agent) that logs performance, tracks session outcomes, and runs retrospectives. It learns which tasks succeed on the first try and which need tighter guardrails. Which prompts produce better code. Which CI failures are flaky vs real.
Agents build features → orchestrator observes what worked → adjusts how it manages future sessions → agents build better features. The system doesn't just run agents. It gets better at running them over time.
And since the orchestrator was built by the agents it orchestrates, and those agents wrote the self-improvement system that now makes them more effective... yeah. It's recursive. The tool is improving itself through the agents it manages.
I think this is why orchestration matters more than any individual agent improvement. The ceiling isn't "how good is Claude Code at TypeScript." It's "how good can a system get at deploying, observing, and improving dozens of agents working in parallel." That ceiling is much higher. And it rises every time the loop runs.
What's next
The orchestrator works. The bottleneck has shifted to how tightly the human-agent loop can run. Three things I care about most:
Talk to your agents from anywhere. Right now you need to be at your desk. That's dumb. You should be able to message the orchestrator from Telegram or Slack — check status, approve a merge, redirect an agent — while you're on a walk. The human doesn't need to be in front of a terminal.
Tighter mid-session feedback. Agents drift. They start solving the wrong problem, over-engineer a simple fix, go down rabbit holes. The orchestrator needs to check agent work against the original intent and inject course corrections before they've burned 20 minutes going the wrong direction. Not just reacting to CI failures after the fact.
Automatic escalation. Agent can't solve something? Escalate to orchestrator. Orchestrator needs judgment? Escalate to you. Right now these handoffs are manual. They should be automatic — you only see things that genuinely need a human decision. Everything else resolves itself.
Beyond that: a reconciler for automatic conflict resolution between parallel agents, auto-rebase for long-running branches, Docker/K8s runtimes for cloud deployments, and a plugin marketplace for community contributions.
Try it
The repo is live: github.com/ComposioHQ/agent-orchestrator
Full metrics report: metrics-v1
If you're running parallel AI agents with bash scripts and hope — we were there a week ago. This is what comes next.
Use ao to build ao
You can use Agent Orchestrator to contribute to Agent Orchestrator. That's literally how it was built.
ao init --tracker github --agent claude-code --runtime tmux
ao start --issue 42
Pick an issue, point an agent at it, let it work. The repo has solid test coverage (3,288 cases), CI that catches real issues, and Bugbot reviewing every PR automatically. Your agent gets the same feedback loop ours did.
We're looking for:
- New plugins — agent runtimes, trackers, notifiers, terminal integrations
- Docker/K8s runtime — run agents in containers instead of tmux
- Reconciler — automatic conflict detection between parallel agents
- Better escalation — smarter rules for when agents should ask for help
I'm building Agent Orchestrator and the integrations layer at Composio, and we're hiring: jobs.ashbyhq.com/composio.
Right now, 30 Claude Code processes are running, building the next set of features. The orchestrator is orchestrating its own improvement. Turtles all the way down.